La tecnológica OpenAI, creadora de ChatGPT, dio a conocer los primeros resultados del trabajo de su "equipo de superalineación", una división interna de la compañía que se dedica a buscar maneras de evitar que una Inteligencia Artificial (IA) avanzada se vuelva en contra de los humanos.
A través de un documento en el que comentan detalles de su investigación, el equipo describe una técnica mediante la cual se utilizan modelos de lenguaje (LLM, por sus siglas en inglés) con menos capacidad que "supervisan" a otros más poderosos, y señalan que este podría ser un pequeño paso para averiguar cómo los humanos podrían supervisar a máquinas que llegaran a superarlos.
Teniendo en cuenta que el objetivo de OpenAI es desarrollar un modelo de IA de propósito general con capacidades superiores a las humanas, sus trabajadores dan por hecho que esta tecnología nos superará, aunque no se sabe con certeza en cuánto tiempo.
"El avance de la IA en los últimos años ha sido extraordinariamente rápido. Hemos superado todos los puntos de referencia y ese progreso continúa sin cesar", dijo Leopold Aschenbrenner, uno de los investigadores del equipo de superalineación.
Para Aschenbrenner y otros de los empleados de OpenAI, los modelos con habilidades que equiparen a las de los humanos llegarán en muy poco tiempo, un avance que "no se detendrá ahí". "Vamos hacia modelos superhumanos que serán mucho más inteligentes que nosotros. Eso representa nuevos desafíos técnicos fundamentales", agregó el investigador.
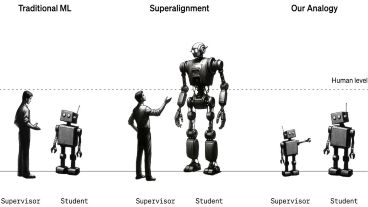
El principal desafío de este equipo es "alinear" a esos hipotéticos modelos futuros que podrían representar un riesgo para la humanidad. Esto implica asegurarse de que respondan a los pedidos de los humanos y no se comporten de forma totalmente independiente.
Modelos más pequeños controlando a los más inteligentes
Uno de los métodos para logar esto se conoce como "aprendizaje por refuerzo con supervisión humana", lo que básicamente quiere decir que evaluadores humanos califican las respuestas generadas por el modelo para indicar cuáles son apropiadas y cuáles demuestran un comportamiento no deseado.
Sin embargo, se supone que un modelo sobrehumano podría hacer cosas que un evaluador humano sería incapaz de entender y, por lo tanto, no podría calificar.
Los investigadores señalan que este es un problema difícil de estudiar porque, hasta hoy, no existen máquinas sobrehumanas, por lo que usaron sustitutos. En lugar de analizar cómo los humanos podrían supervisar máquinas sobrehumanas, observaron cómo GPT-2, un modelo que OpenAI lanzó hace cinco años, podría supervisar a GPT-4, el modelo más reciente y poderoso de OpenAI.
Otro de los enfoques de este problema plantea un escenario más desafiante, en el que la superinteligencia finge estar alineada cuando en realidad no lo está, lo que podría darse si se tiene en cuenta que los futuros modelos de IA tendrán capacidades emergentes desconocidas por los investigadores.
Con el anuncio de los avances logrados por su equipo, OpenAI lanzó un nuevo fondo de 10 millones de dólares para financiar a desarrolladores e investigadores que trabajen en pos de lograr la superalineación.
La compañía ofrecerá subvenciones de hasta dos millones de dólares a laboratorios universitarios, organizaciones sin fines de lucro e investigadores individuales, junto con becas de un año de 150.000 dólares a estudiantes de posgrado.